Content Enrichment by Data Integration with CRISP API
Woonsan Ko
2017-07-07
Introduction
Many people look to semantically enriched content in their web properties to provide their users with better digital experiences. Smartly tagged content can give a better search experience by letting time-strapped users quickly find the right content at the right time. The metadata used for this tagging can come from a variety of sources, including external taxonomy data, an external PIM (Product Information Management) system or an external (Commerce) RESTful APIs and, with proper platform and solutions, can be accomplised without worrying about costly and complex data migration and synchronization between CMS and external backend systems.
Cost-effective solutions for personalization, such as topic-based grouping of internal/external content possibly with hierarhical relationships or linking internal/external content based on relationships in the business domain, are available for those ready to enrich thier digital experience.
Companies interested in these solutions probably don't want to waste time on looking at a big mumbo jumbo product suite or technologies, but want to be very practical, starting with real user stories and finding the proper technologies for the stories. That's why I'm introducing CRISP API as the most adequate and practical framework solution for almost all the backend integration and interoperability to enable your content enrichment stories of this kind.
What is CRISP?
CRISP is a backronym for Common Resource Interface and Service Provider. CRISP gives a nice solution for Content Enrichment focused digital experience scenarios by using external API integrations with various backends. By adopting and implementing proper design patterns (e.g, "Broker", "Generic Repository" and "Generic Object Model" patterns), it ensures highly available, high performing, secure, maintainable, extensible and cost-effective solutions.
What problem does CRISP solve?
Suppose you need to enrich content delivery and authoring by connecting external data sources to your content and exchanging information across applications. What are the typical problems encountered in this secenario?
Let's take a look at a wireframe of a typical commerce-enabled page as an example:
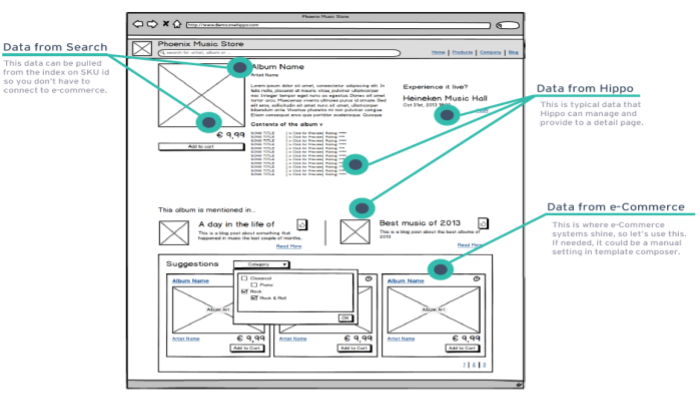
Data such as name, description and price are coming from a PIM (Product Information Management) system based on a SKU number. The page renders various content that is managed through the CMS. Some related and recommended products can be retrieved from an external Commerce API such as Bloomreach Commerce API, too. That is, when you have a product related page the page could be linked to one or multiple products, to related and recommended products, and possibly to any targeted ads or campaigns. This is a typical example of content enrichment by data integration.
You may replace the external data sources (PIM and Commerce API) with something else, such as external taxonomy management system and any other external RESTful services, but you will end up seeing almost the same integration pattern again - regardless of what kind of domains or technologies you need to integrate with.
By the way, when integrating with external data sources in CMS, there are usually two approaches:
• Synchronization: Migration of data from external source to content in CMS. Should be synchronized to be consistent.
• Tagging: Adding only (semantic) metadata to content in CMS to relate to external data source. Should read most external data associated with the content at runtime (in authoring or delivery applications).
In this article, I'd like to narrow the scope (of scenarios to cover) to the Tagging approach for conciseness. If the Tagging approach is applicable to your use cases, then it can give the following advantages in general:
• You can keep a single source of truth in your organization. For example, a PIM (Product Information Management) system can be managed as the single system responsible for all the product data in your organization. By having only product metadata such as SKU number (which rarely change) in a CMS document, you don't have any duplicate data in the CMS and you don't worry about content migration and synchronization because all the details of the product will be retrieved at runtime. You may replace the PIM (Product Information Management) system with something like an external taxonomy management system, for example.
• It is more likely that your software module for the integration becomes simpler and easier to maintain with the Tagging approach. It can give highly available, high performing and cost-effective solutions If it is designed well for the quality attributes.
Why a big If there? The reason is that, in my experience, many implementation efforts don't include the necessary quality attributes and technical considerations which they should have been designed based on.
Let's take a look at the following example diagaram that depicts how an integration module is typically designed in a higher level:
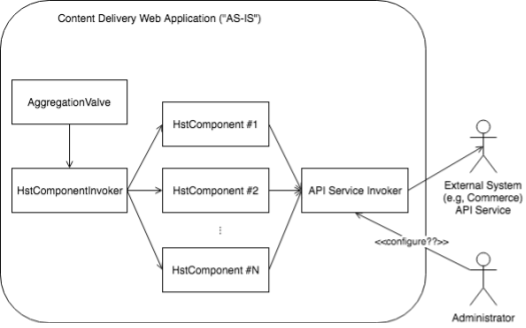
Suppose the page renders a product related piece of content, associated product information (retrieved from PIM system), and related and recommended products in a grid. For example, one of HstComponents retrieves product information for a specific product from PIM system, another HstComponent retrieves the same product information for the same product and decorates its rendering part together with product related content, another HstComponent also needs to retrieve related or recommended products, and so on. The development team decides to introduce a service component ("API Service Invoker") retrieving data from external systems, simply hoping it will help.
The design looks good at first, but as soon as they start implementing it they realize that it is a much more complex problem. For example,
• Multiple HstComponents often need to retrieve the same data (e.g, product information data for a specific product) from the same external system. If each HstComponent is implemented without any help from a better architecture, each HstComponent will probably retrieves the same data from an external system again and again, making remote calls, even sequentially. This will leads to notable inefficiency and late response time of the page.
• Someone may figure out that they can store the product information data in a shared location using HstRequestContext#setAttribute(name, value), for instance, in order to avoid multiple remote calls to the backend system for the same data. This sounds slightly better, but this time, the code becomes longer than expected and harder to maintain. The more to share between HstComponents, the more complex it becomes.
• Some data can be cached for a time interval (e.g, 1 minutes, 1 hour, 1 day and so on). For example, if it is known that the update frequency of the backend PIM system is once every night, then you may decide to cache the data from PIM system for 1 day to be more efficient and performant. If you want to enable enterprise-ready caching as well, you will probably need to improve the design for the requirements, too. This can easily increase the cost of the development.
How about security? Most external RESTful Services provide OAuth2 based security in communications nowadays. If you have to let someone in your team research and develop OAuth2 integration, you end up increasing the estimation of the project. Why can't we leverage any industry best practices and frameworks (such as Spring Framework OAuth2 module) for this kind of integration pattern? Indeed, isn't it what we often meet in real projects as a pattern?
We need a better approach, best practices and solutions to this problem. This problem has been something we have had to solve again and again. No problem needs to be solved twice! If it is a very typical problem in the content enrichment digital experience scenarios around us, we need to consider a better framework as a generic solution. That's why I'm introducing CRISP API below.
Solution Architecture with CRISP
The following shows a higher level view about a solution to solve the problem explained above in a generic way.
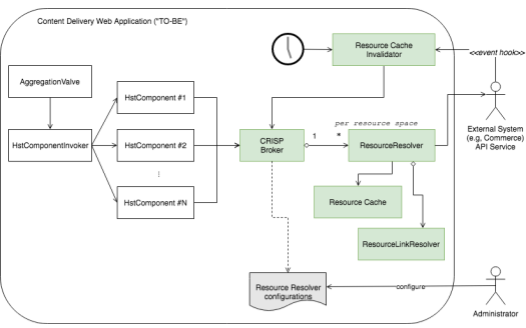
Basically, the solutions adopts the following design patterns:
• Broker pattern: Every component (e.g, HstComponent, Collector, CMS Plugin, etc.) must retrieve data from external systems through CRISP Broker component (ResourceServiceBroker interface in CRISP) only. So, this broker can be the single component that understands what the call information consists of (e.g, resource space, request path, parameters, etc.), which external system should be invoked, whether or not the result can be cached, and so on.
• Generic Object Model pattern: Every result from the backend systems should be represented as Resource objects (Resource interface in CRISP) whether the result is formatted in JSON, XML, POJO or whatever. This simplifies the integration effort remarkably. Without this generic object model abstraction, you will need to understand and map an external backend system's specific object model in implementations. In most cases, that kind of strict mapping effort turns out to be unnecessary, especially when you just use the Resource objects in (FreeMarker or JSP) templates since Resource interface in CRISP provides all the necessary properties and methods by default.
• Generic Repository pattern: In combination with Generic Object Model, even the resource retrieval component (ResourceResolver interface in CRISP), which is communicating with an external backend system, can be generalized too as its return values should be Resource object (as in Generic Object Model pattern), and request path information and parameters can be generalized relatively easier.
So, when invoking the broker component ("CRISP Broker" in the diagram or ResourceServiceBroker interface in CRISP) in a component, the broker resolves a proper ResourceResolver by the given resource space name, and invokes the ResourceResolver component by passing the rest arguments. ResourceResolver can be configured with a ResourceCache, so it can find and return resources from either its local cache or external backend system, and put the resource into the cache, based on cache configurations.
Optionally, when a template needs to generate a link to the external resource object, typically by using CRISP tag library (e.g, <@crisp.link ... /> in FreeMarker templates), ResourceLinkResolver (that can be configured with a FreeMarker template for link generation) can be invoked for the ResourceResolver. The administrator can change the configurations for each ResourceResolver (e.g, OAuth2 client ID and secrets) stored in the CMS, and any changes will be applied right away at runtime without having to restart the system.
Also, CRISP adopts the following technical elements to leverage industry best practices:
- Spring Framework, for dependency injection in general
- Spring Framework's RestTemplate, for RESTful API integration
- Spring Security Framework, for security integration
- Spring Security OAuth2, for OAuth2 security integration
- Spring Framework's Cache library, for cache management
- Apache FreeMarker, for template based configuration to generate links to external resources
These are the basic ideas behind CRISP and how it wants to solve the problem. You can find more architectural details in CRISP documentation.
Example Code
So, how could our code be simplified by using CRISP? Let me show a simple HstComponent code example:
@Override
public void doBeforeRender(HstRequest request, HstResponse response) {
// broker will find a proper ResourceProvider by the resource space,
// ‘productCatalogs’ and invoke a message exchange route internally.
// And, it will return a generic Resource container as a result.
ResourceServiceBroker broker = CrispHstServices.getDefaultResourceServiceBroker();
// Or, use HstServiceRegistry in CMS plugin code like the following:
// broker = HstServiceRegistry.getService(ResourceServiceBroker.class);
final Map<String, Object> variables = new HashMap<>();
variables.put("fullTextSearchTerm", "foo");
Resource productCatalogs =
broker.findResources("productCatalogs",
"/products?q={fullTextSearchTerm}",
variables);
// Set productCatalogs resource object to request to render in template.
request.setAttribute("productCatalogs", productCatalogs);
// ...
}The point is, your project implementation to retrieve data from various external backend systems will be really simple, as is seen in this example. You don't need to take care of any caching or any configuration updates yourself. You can configure the caching for each resource space through the repository configuration at /hippo:configuration/hippo:modules/crispregistry/hippo:moduleconfig/crisp:resourceresolvercontainer/.
Your code will be extremely transparent and easy to maintain, ensuring highly available, high performing and cost-effective integrations.After getting the broker service component (which is normally a singleton in an application), you can retrieve resource objects by passing the resource space name (e.g, "productCatalogs"), the resource path you want to invoke (e.g, "/products", "/products/123", "/products?q=mobile", etc.) and optional variables map by which the resource path argument can be expanded.
Suppose the external backend system is a RESTful web service at http://localhost:8080/example-commerce/api/v1(which is actually configured in the repository configuration) and the product data is provided by the relative path, /products. Then the service call in the example code will invoke http://localhost:8080/example-commerce/api/v1/products?q=foo under the hood, and return a Resource object encapsulating some JSON data response like the following:
[
{
"SKU": "12345678901",
"description": "MultiSync X123BT - 109.22 cm (43 \") , 1920 x 480, 16:4, 500 cd\/m\u00b2, 3000:1, 8 ms",
"name": "CBA MultiSync X123BT",
"extendedData": {
"title": "CBA MultiSync X123BT",
"type": "Link",
"uri": "Awesome-HIC-Site\/-\/products\/12345678901",
"description": "MultiSync X123BT - 109.22 cm (43 \") , 1920 x 480, 16:4, 500 cd\/m\u00b2, 3000:1, 8 ms"
}
},
{
"SKU": "12345678902",
"description": "PA123W, 68.58 cm (27 \") LCD, 2560 x 1440, 6ms, 1000:1, 300cd\/m2, 1.073B",
"name": "CBA PA123W",
"extendedData": {
"title": "CBA PA123W",
"type": "Link",
"uri": "Awesome-HIC-Site\/-\/products\/12345678902",
"description": "PA123W, 68.58 cm (27 \") LCD, 2560 x 1440, 6ms, 1000:1, 300cd\/m2, 1.073B"
}
},
//...
]You can simply iterate and retrieve each field and descendant Resource object in the FreeMarker template very easily:
<#if productCatalogs?? && productCatalogs.anyChildContained>
<article class="has-edit-button">
<h3>Related Products (from JSON message)</h3>
<ul>
<#list productCatalogs.children.collection as product>
<#assign extendedData=product.valueMap['extendedData'] />
<li>
<@crisp.link var="productLink" resourceSpace='demoProductCatalogs' resource=product>
<@crisp.variable name="preview" value="${hstRequestContext.preview?then('true', 'false')}" />
<@crisp.variable name="name" value="${product.valueMap['name']!}" />
</@crisp.link>
<a href="${productLink}">
[${product.valueMap['SKU']!}] ${extendedData.valueMap['title']!}
</a>
(${product.getValue('extendedData/description')!})
</li>
</#list>
</ul>
</article>
</#if>As you can see, Resource interface provides necessary properties and methods for templating. e.g, #isAnyChildContained(), #getChildren(), #getValueMap(), #getValue(String relPath), etc. Also, with <@crisp.link ... /> tag support, you can generate links to the external resource objects through the backend ResourceLinkResolver components. Please refer to CRISP documentation for more details.
Demo Project
You can build and test the demo project included in the CRISP project itself. Clone the project and run the demo from a specific tag (e.g, hippo-addon-crisp-2.0.0 for v2.0.0) branch:
$ git clone --branch hippo-addon-crisp-2.0.0 https://code.onehippo.org/cms-community/hippo-addon-crisp.git
$ cd hippo-addon-crisp
& cd demo
$ mvn clean package && mvn -Pcargo.run
Also, you can use CRISP API in CMS plugin code or relevance collector code. Try to edit the "Related Products" field in a news article document in the CMS. Then you will see the popup dialog that retrieves external product data at runtime through CRISP API.
Take a look at CommerceProductDataServiceFacade.java, an example using the External Document Picker Forge plugin.After startup, visit http://localhost:8080/site/ and navigate to a new article detail page. Then you will see a very simple example including external product data in the news detail page. Take a look at NewsDetailComponent.javaand newspage-main.ftl page.
In the demo project, there are multiple pre-configured resource spaces in the repository configuration at /hippo:configuration/hippo:modules/crispregistry/hippo:moduleconfig/crisp:resourceresolvercontainer/: "demoProductCatalogs", "demoProductCatalogsXml", "demoSalesForce" and "demoMarketo".
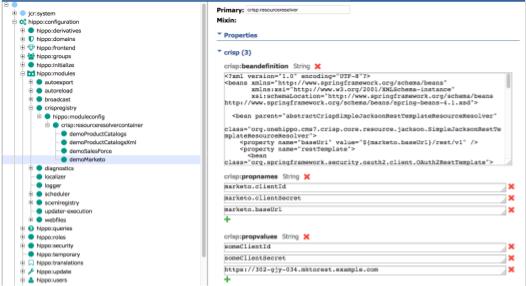
The first two resource spaces, "demoProductCatalogs" and "demoProductCatalogsXml", are examples of integration with the local demo RESTful services for product data at http://localhost:8080/example-commerce/api/v1/products and http://localhost:8080/example-commerce/api/v1/products.xml.
See ProductsController.java in the demo project to see how the example was implemented. The "demoProductCatalogs" resource space is an example to show how to retrieve, iterate and traverse JSON-based Resource objects, whereas the "demoProductCatalogsXml" resource space is an example with XML-based Resource objects instead.
The other resource spaces, "demoSalesForce" and "demoMarketo", are examples to show how you can use OAuth2-based RestTemplate in the repository configurations. Please take a look at those configurations if you need to communicate with OAuth2-based RESTful services as backend systems.
CRISP framework initializes and loads each ResourceResolver component for each resource space by reading the crisp:beandefinition property which simply contains Spring Framework bean definitions in XML. You can define variables through the pairs of crisp:propnamesand crisp:propvalues, and use the variable names in crisp:beandefinition property without having to put physical information in the crisp:beandefinition property itself.
The point is, almost everything including security, cache, link resolution, etc. are totally configurable through the repository configuration (crisp:beandefinition, crisp:propnames and crisp:propvalues), and Spring Framework, Spring RestTemplate, Spring Security Framework, Spring Security OAuth2, Spring Cache, etc. are fully leveraged in order to adopt the industry best practices and avoid unnecessary costs in development and maintenance while ensuring highly available, high performing, manageable, maintainable and cost effective solutions.
Summary
CRISP provides a nice solution for Content Enrichment focused digital experience scenarios using external API integrations with various backends in a very cost effective manner. By adopting and implementing proper design patterns (e.g, "Broker", "Generic Repository" and "Generic Object Model" patterns) and industry best practices and technical elements (e.g, Spring Framework, Spring RestTemplate, Spring Security Framework, Spring Security OAuth2, Spring Cache, etc.), it ensures highly available, performant, secure, maintainable, extensible and cost-effective solutions.
Your project implementations to retrieve data from various external backend systems will be simple thanks to CRISPframework. You don't need to take care of any caching or any configuration updates by yourself. Simply by configuring the cache for a resource space through the repository configuration at /hippo:configuration/hippo:modules/crispregistry/hippo:moduleconfig/crisp:resourceresolvercontainer/, your project code will be extremely transparent, easy to maintain and highly modifiable under time/budget constraints.
In the demo project of CRISP, you can find various examples communicating with a simple RESTful service backends or OAuth2-based external backends systems such as SalesForce and Marketo. Just by configuring the properties, you will be able to see how it works easily, and so you can apply almost the same configurations to your own projects. Almost everything including security, cache, link resolution, etc. are configurable through the repository configuration.