GraphQL in eCommerce
Paul Edwards
2021-02-11
How Commerce is Evolving
Old commerce stacks were typically monolithic dinosaurs - they made it hard to innovate, were slow to iterate on and frequently suffered from scaling issues. It was incredibly difficult to deliver on the promise of personalization - or even website optimization. Commerce stacks had to evolve.
There have been many iterations along the way - from service-based architectures (splitting the stack up), to Javascript-based storefronts (offloading work from the web server) - however, we are currently seeing the industry coalesce around GraphQL (Short for Graph Query Language). Before we delve into the “Graph”, let’s have a look at the commerce stack as a whole:
If we think of what the commerce site is trying to achieve, it is to make the experience of buying as personal and as painless as possible for the buyer. As the old adage says - it is about putting the right product in front of the right person at the right time.
This means listening to all of the signals that customers generate (be they onsite, SMS, email or even offline data) and using all of those to tune the experience on an ongoing basis.
We can think of the commerce stack from an experiential perspective.
The Experiential Perspective:
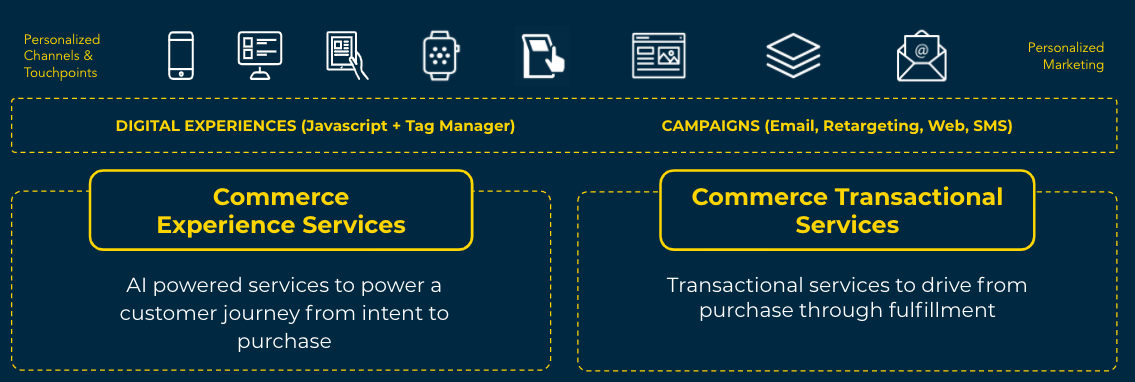
Front end - This layer consists of clients such as web storefronts, chatbots, IoT devices, clienteling apps, email campaigns and more. It both consumes and provides data to the Commerce Experience layer. Similarly it queries and transacts with Commerce Transactional Services. All of these transactions and exchanges of data are as and when required.
Commerce Experience Services - This layer is made up of all of the services which power a customer journey. It collects behavioural information and utilizes AI algorithms to tune the site on an ongoing basis as well as providing content management and marketing services.
Commerce Transactional Services - This layer provides all of the commerce transactions. It is the workhorse which processes orders, manages customer addresses and provides fulfillment services.
Benefits of the Experiential Architecture
For the purposes of this blog post, I am borrowing the phrase ‘Experiential architecture’ from the realm of building architecture as it gives us a vehicle to neatly separate the front ends of this world (Storefronts, emails, call centers) and the commerce back-ends from the layer which provides the ability to manage interactions.
This ‘Experiential architecture’ gives commerce organizations the ability to utilize all of the analytical data they are generating around their customers and products across all of their touchpoints - without relying on the underlying eCommerce platforms and independently of the channels people are interacting with.
Having experience services grouped together within this layer of the architecture enables organizations to achieve a level of pervasive personalisation due to a shared understanding of the Product and Customer Graphs that is very difficult to achieve in point system integrations.
For example, the architecture allows the organization to understand, analyze and segment people based on their engagement with marketing emails, products, purchases, time since last site visit, or any other metric - and to tune not only onsite banners but home page, landing pages, product grids - in fact the whole of the site and wider experience on an ongoing and consistent basis.
If we think about how this applies to search, category and recommendation grids, the architecture learns to optimize based on core KPIs - typically Revenue Per Visit (RPV) or Margin in a way that is specific not only to each and every individual category or search term, but is also optimized for the individual customer segment (and even specific customer) coming through the site. Additionally, the layer provides the tools for merchandisers, publishers or data scientists to apply their own KPIs at scale against these grids (e.g. X-factor, Y-factor, coolness, newness).
The Role of the Graph
As noted above, the industry as a whole is coalescing around the concept of the graph - as a side note, the graph (GraphQL) was invented by Facebook in 2012 as a mechanism for simplifying the integration of APIs.
In a nutshell, GraphQL enables clients to request exactly the data that they want and it responds back with exactly that data and nothing more. The clients do not need to know anything about the API that the graph is talking to. This means that clients no longer have to talk to lots of APIs to integrate but instead they can talk to one - the graph. As an example, I could request ‘products’ from a search provider, then extend the query as the customer decides that they want to know if the product is in stock at their local store. The key benefit here is that the data flowing through the graph is a direct reflection of the UX interaction and therefore there is little bloat in terms of unwanted fields - the client isn’t shifting lots of data from endpoints and trying to glue it all together itself.
There are other benefits as well:
The ability to easily discover the functionality of the graph (introspection) just by interacting with it.
The fact that the organisation has a single graph - e.g. there is exactly 1 definition of a product or price rather than definitions which may conflict across multiple interfaces and multiple host systems.
There are also some newly introduced challenges:
Caching at the graph layer,
Performance and complexity limits
The Federated / Stitched Graph
One of the massive benefits of graph technology is that it enables organizations to establish a single graph and for suppliers of systems to be integrated into this graph via mechanisms such as federation or stitching.
An organization therefore can take suppliers’ implementations of graph technology and not have to customize them - they remain supportable and can be upgraded as new versions are released with minimal drama.
The Federated / Stitched organization looks like this:
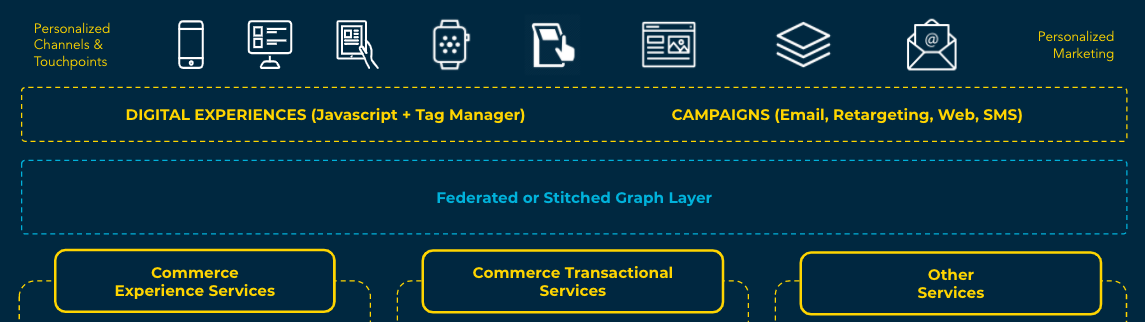
Integration complexity for clients is vastly reduced - sometimes to a single interface. Services are encapsulated inside their own graphs and the graph as a whole is easily extensible for complex use cases.
A Practical Use Case: Real-Time Pricing & Availability
Consider the scenario where an eCommerce organization wants to provide their customers with real-time (perhaps personal) pricing or availability. It doesn’t make sense to update these values in the search database as this is a non-scalable approach (it may work well for small indexes but it becomes an ever expanding problem as the index grows).
Graph is a great solution here. Imagine we implement a pricing authority inside our internal services graph and the client can then call this service from the graph as and when it makes sense (typically not on lister page views as that would generate a lot of requests - but perhaps on product detail page views instead):
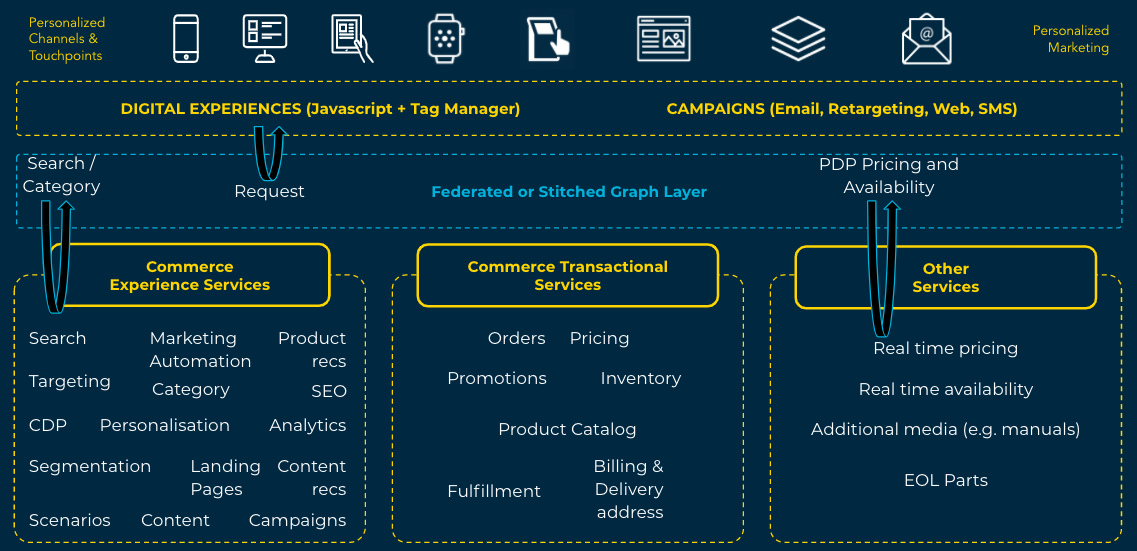
As we can see above, the pricing service is only accessed when it is needed - this can lead to orders of significance savings in the scaling (and hence, cost) of the service.
Final Thoughts and A Note of Caution
Looking at eCommerce from an experiential perspective affords us a great opportunity to see how and why architectures are changing - and through this document I have made much of how GraphQL and graph technologies as a whole are helping organizations to reshape their internal integration landscapes. However, graph itself is not a magic bullet and there will always be use cases for a well-tuned, succinct API (such as a REST API).
Autosuggest (in eCommerce) is a good example of this - it’s the drop down that happens whenever you are typing into a search box. The fundamental utility of Autosuggest is to finish a potential customer’s thoughts for them by suggesting things that they are most likely to want to engage with or buy - whilst they are in the act of typing. In its purest form, it is to remove the friction between thought and action. It is therefore one of the most performance-sensitive API calls on the whole of an eCommerce website and as such, the performance overhead of a GraphQL call will probably detract from the overall experience (by slowing it down).
More than that, the function of the autosuggest query itself is never going to change or extend and hence the flexibility of GraphQL as a whole - asking for exactly what I want - in this scenario is somewhat redundant as I will always ask for the same thing.
Whilst GraphQL is great from a query perspective as it allows client applications to talk to multiple back end platforms (possibly point solutions) with ease, it does not help with data sharing between these back end systems - it doesn’t provide organisations a unified data layer which helps them to achieve pervasive personalisation across all touch points through understanding of both customer and product.
Either way, it is clear that GraphQL is bringing about change in the eCommerce landscape and, used appropriately, can be a huge benefit to organizations as a whole.
For more information on GraphQL, tune into my next blog post that will explore this topic further. For now, I hope you enjoyed reading this article! I’d love to hear any comments or feedback so please feel free to reach out to me - [email protected] - or connect with me on Linkedin.