DREAM on EIRE: Agility Matters in Relevance
Woonsan Ko
2017-12-12
"I'm lost, man." It was Joe, an experienced engineer in Digital Experience projects for years, that sighed after a while. Everything sounded great when he smiled and talked about his experiences with our products and solutions, but when I asked about the recent Relevance implementation, I saw his smile dissolve on his face. "I have done my best to realize data collections and personalization to meet the requirements," he continued, "but it takes too much time to implement just a single data collector. Several Java classes including Plugins, ExtJS scripts and various repository configurations." According to Joe, even if he delivers fixes sprint after sprint, business users remain dissatisfied because they have to wait 2 weeks again and again even for a simple improvement in the data collection model while missing business opportunities. He whispered piercingly to my heart: "It's hard to implement such simple things in time with Relevance."
Agility, the missing part
Time flies. After several seasons passed, I started thinking about what's wrong on earth in the Relevance implementation cycle and why the Relevance realization cycle cannot be fast enough. To understand the problem, I depicted the cycle ("DAME" cycle) from the viewpoint of business people who dreamed of the ideal digital relevance management on their web properties:
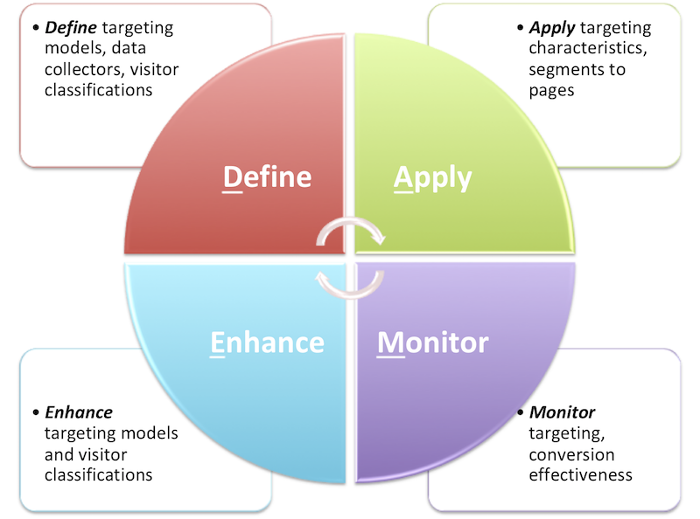
There are four phases in Relevance realization cycle:
- Define phase: Business experts determine the variables to deduce from various input data which can be extracted from the visitor or from the environment surrounding the visitor's context such as time, weather, etc. For example, they want to collect visitor's "content interest type" on each page visit (e.g, "news", "events", etc.) and find out the "most frequent content interest type" of the visitor from the page hit logs. In this case, "content interest type" per request and "most frequent content interest type" per visitor are the variables they need to deduce in their targeting model.
- Apply phase: Business experts or webmaster apply personalization variants in Channel Manager, using the characteristics defined by combinations of the deduced variables.
- Monitor phase: Business experts or data analysts monitor the personalizations in reality to see how effective it is in the visitor's journey on their web properties.
- Enhance phase: Business experts improve the targeting model to help their visitors with a better personalization support, based on the monitoring data and analysis. The improvement ideas are passed to the Define phase to update the model.
The relevance realization process is in spiral cycles. Based on prior knowledge base, business experts want to collect only the "content interest type" variable initially, but visitor patterns discovered in Monitor and Enhance phases make them wish to collect more data such as "occupation" or "gender" of visitors, for instance. Combining those new variables together with "content interest type", they can provide visitors with a better personalization experience. The discovery in an iteration cycle must be used to improve the targeting model in the next iteration cycle. Visitors surrounded by the environment are "living" people, not predefined static objects!
What has been missing in the Digital Experience Management in many projects? It is Agility. Relevance Realization is the key to the Digital Experience, and Relevance implies Agility by definition since it is for real people, living in the real world, flocking together and moving into various directions. Agility should have been the core factor of Digital Experience and Relevance Realization process from the beginning!
It starts from Define phase
Joe's problem lies in the Define phase. When business experts define variables to deduce from various input data, he has to implement a targeting data collector for each variable. Otherwise, they cannot proceed to Apply phase. He has to implement the following for a collector ("foo" variable for instance):
- FooCollector.java and FooScorer.java, invoked by the Targeting Service in the delivery tier for each page hit.
- FooCharacteristicPlugin.java and FooCharacteristicPlugin.js, used in Characteristics Management UI in the authoring tier by business experts. Without these, business users cannot define characteristics nor use Experience Optimizer UI at all.
- FooCollectorPlugin.java and FooCollectorPlugin.js, used in Alter Ego UI. Without these, business users cannot simulate the channel preview with different combinations of characterstics.
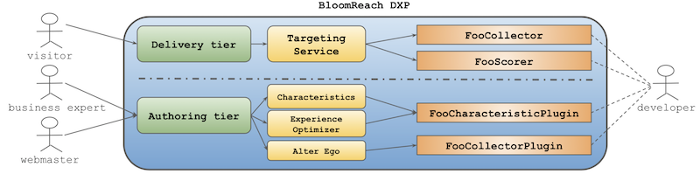
At this moment, I came to an understanding about what the main problem was. It is not Joe's problem, but there are too much to implement, test and maintain for a single variable, which has been an hindrance to Agility. If business experts have to wait for a next software development sprint to get a fix for something simple, they lose business opportunities in coming weeks or months. The Define phase, including data collector implementations, must be faster and more agile.
On EIRE (Expressional Inference Rule Engine)
Solution didn't come easy even if I managed to understand the problem. Also, I didn't want to introduce another problem, making it more complex, to solve one problem. But, simplicity doesn't come for granted. Many pages were written and torn away in my mind until hearing voices in the EIRE.
I hear voices in the air
I hear em’ loud and clear
Telling me to listen
Whispers in my ear
Nothing can compare
(from the lyrics of Invincible)
Here's the simplicity the voices whispered in my ear:
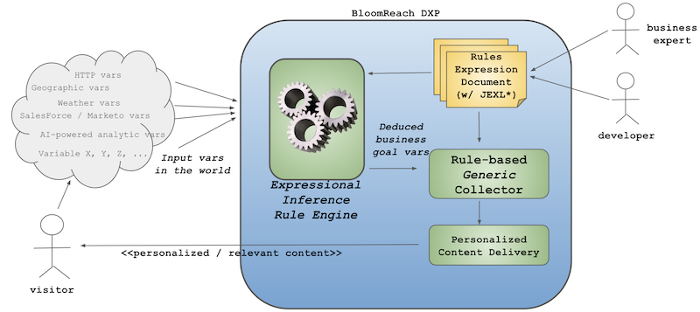
- All the variables we want to deduce in collectors are categorical. Even if the input data is an interval variable (such as weight or height), we need to label it for business users to select those classifications in characteristics.
- The concept of inference engine as forward chaining style can be adopted to build a simple generic collector engine by embracing an expression language such as Apache Commons JEXL.
- Each data collection rules can be defined in a document without having to implement and deploy Java/ExtJS classes. When publishing the inference rules document, it configures and enables a collector component for the variable automatically. When unpublishing it, it disables the collector.
These are the design concepts for the new experience plugin, Expressional Inference Rule Engine Add-on.
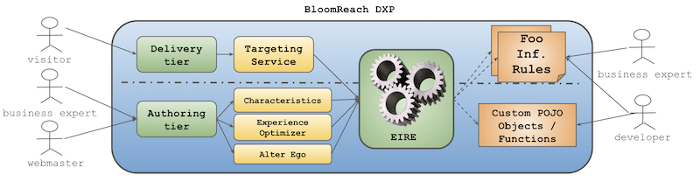
I recommend you all to use the enterprise module right away in your project. Please check it out now: Expressional Inference Rule Engine add-on. My friend, Joe, got excited about this. He can now complete a data collector more than 10 times faster than before. Business folks are very happy about it because the feedback cycle becomes a lot shorter than before, realizing their DREAM (Digital Relevance Experience and Agility Management).
The Relevance Trilogy and its demo project
I gave a presentation in Bloomreach Connect 2017 in Amsterdam about Expressional Inference Rule Engine add-on. See my slides:
Relevance trilogy may dream be with you! (dec17) from Woonsan Ko
You can also build, run and test the demo project. Just follow the README.md.
Enjoy and revive the Agility. May DREAM be with you!