Scalability
Hippo is designed to scale and provides an architecture that can handle your evolving traffic requirements now and in the future.
Horizontal Scalability
At system architecture level Hippo scales out very well. Each of its 3 tiers can be scaled individually. The web tier can run a load-balancer with multiple web servers serving as reverse proxies. In the application tier any number of application servers can be clustered, and since authoring and delivery applications are separated, these can be individually clustered as well. The database tier can consist of a single database server, a cluster of database servers, or master/slave setup.
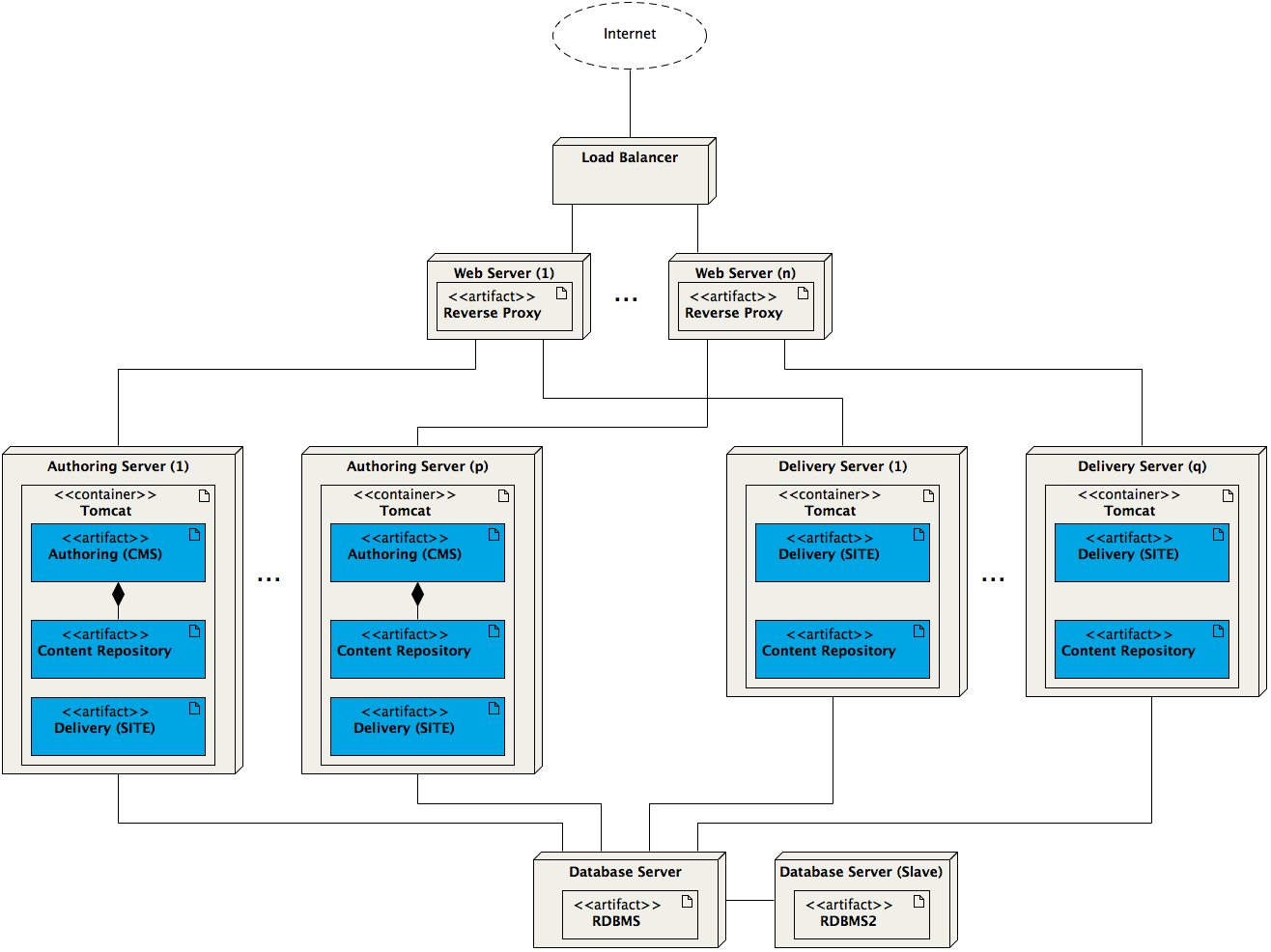
A Hippo application cluster is managed through a journal table in the database which allows individual nodes to keep their content repositories in sync, and newly added nodes to ‘catch up’ automatically. This allows a fast response to quickly evolving traffic requirements simply by adding or removing nodes.
The load-balancer needs to be able to handle sticky sessions for the authoring application. The delivery tier normally does not have this requirement if best practices are followed, although this is up to the implementation.
Vertical Scalability
At application level Hippo’s delivery tier scales up very well too. Through efficient use of available hardware resources and smart caching strategies the number of concurrent requests that can be handled scales linearly with increased CPU speed and number of CPU cores. Especially in a virtualized environment this provides an additional way to respond quickly to changing traffic requirements.