System Architecture
Introduction
Goal
Understand Hippo's system architecture and supported deployment scenarios.
Standard Deployment Scenario: Authoring and Delivery Webapps in a Single Container
The deployment diagram below is a somewhat simplified representation of a standard Hippo system:
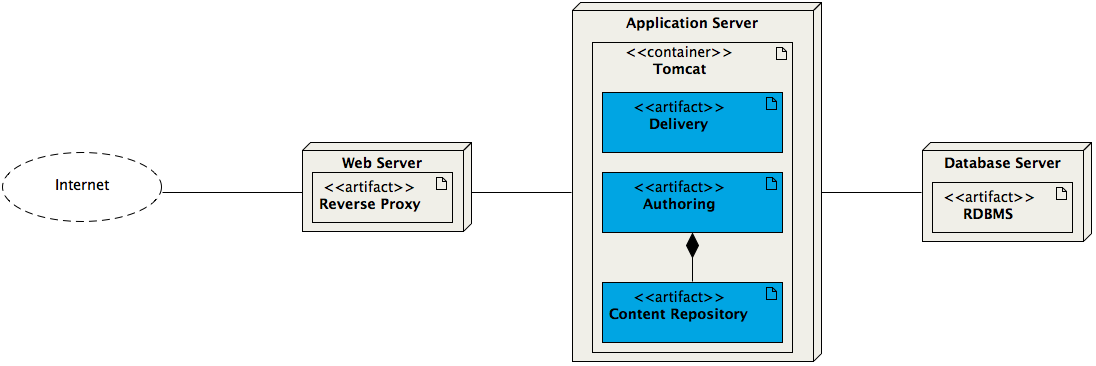
Clearly visible are the three tiers of the system:
- Web Tier
- Application Tier
- Database Tier
Central to the system architecture is the application tier: this is where the actual Hippo applications are running. It consists of an application server which runs a servlet container, typically Apache Tomcat. Hippo's authoring and delivery applications (both Java webapps) are deployed inside this container. A third application, Hippo's content repository, runs embedded inside the authoring webapp.
The database tier consists of one of the supported database servers and is used by the content repository application to store all data. When using the Relevance Module (Hippo Enterprise Subscription required) the database tier additionally contains the Elasticsearch application which acts as one of the needed relevance data stores.
The web tier consists of a web server, typically Apache HTTP Server ("httpd"), which acts as a reverse proxy for the authoring and delivery applications.
Each of the three tiers can be scaled individually. Typically the application tier runs in a clustered configuration.
Alternative Deployment Scenario: Authoring Webapp in Separate Container
Alternatively the delivery webapp may be deployed without the authoring webapp in a separate container, as shown in the deployment diagram below:
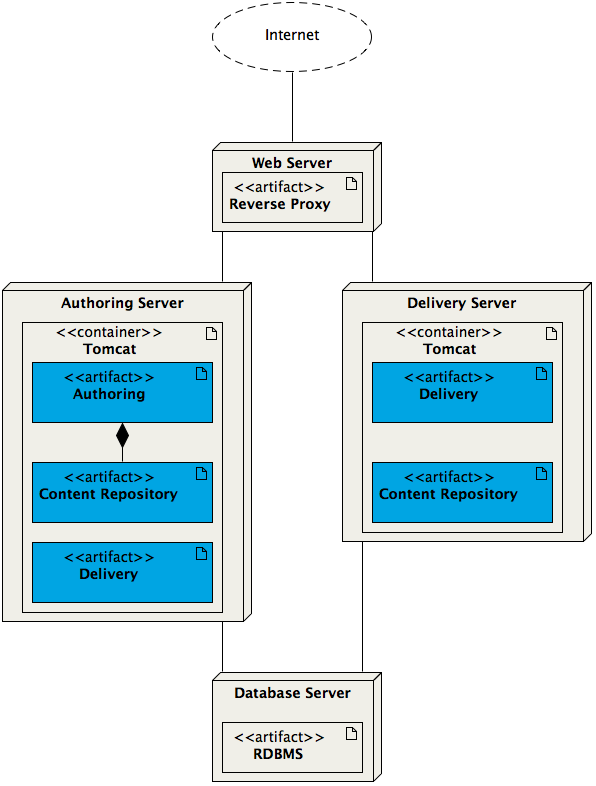
The authoring application needs the delivery application in order to provide the channel previews in the Channel Manager. Therefore an instance of the delivery application is also still deployed in the same container as the authoring application.
The delivery application that is deployed in a separate container accesses a repository application deployed in the same container. The content repository instances in the different containers use the same database for storage, and are effectively running in a clustered configuration.
One advantage of this architecture is that the delivery application can be scaled individually as needed.
Clustering
For clarity the previous two deployment diagrams do not take clustering into account. Typically however Hippo runs in a clustered configuration. In the application tier any number of application servers can be clustered, and in the second scenario described above the authoring and delivery applications can be clustered separately. A load-balancer is added to the web tier in order to distribute traffic across the cluster nodes.
A Hippo application cluster is managed through a journal table in the database which allows individual nodes to keep their content repositories in sync, and newly added nodes to ‘catch up’ automatically. This allows a fast response to quickly evolving traffic requirements simply by adding or removing nodes.
The deployment diagram below shows an example configuration consisting of p clustered authoring nodes and q clustered delivery nodes:
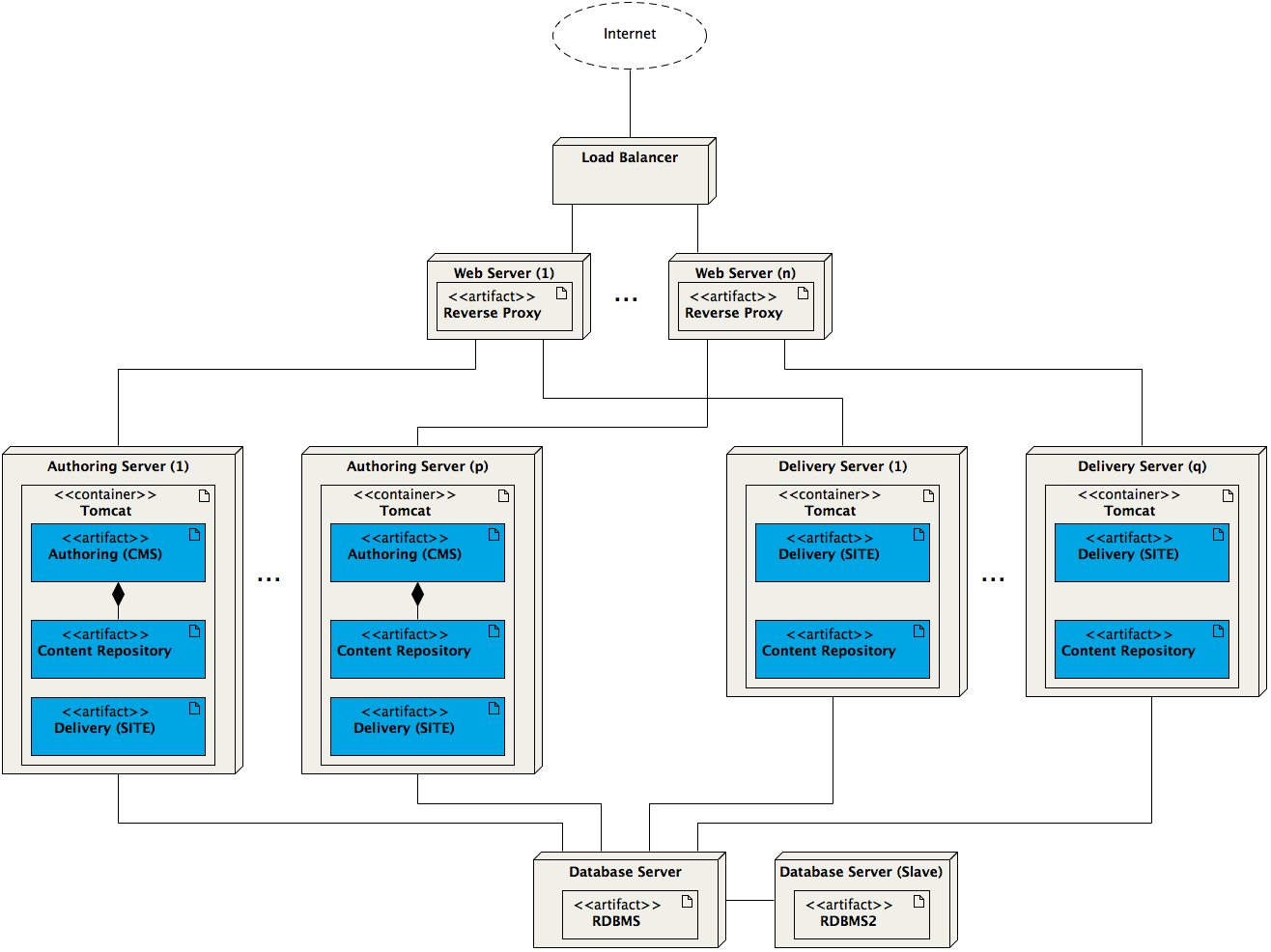
In addition the example contains n clustered web servers and two database servers running in a master/slave configuration.
Other Options
Hippo also supports:
- Deploying the delivery application as ROOT application
- Secure access over HTTPS per site and per URL
- Replication of repository content across a firewall to a DMZ
Further Reading
-
A Bird's Eye Hippo CMS Architectural View Part 1: 10,000 Feet View (blog post by Ard Schrijvers)