Introduction to Expressional Inference Rule Engine Add-on
Introduction
If you have ever tried to implement custom collectors from scratch for the Relevance Module, you may have found it's more work than you initially expected. You need to understand the concepts of Collector, Scorer, CharacteristicPlugin and CollectorPlugin and implement those in Java, Wicket, ExtJS, etc. correctly, spending non-neglectable time and effort. A small mistake in any of those steps could cost more time or lead to a wrong implementation that does not fulfill business requirements in the end. Consequently, the feedback loop between business and development can be broken and there could be no more enhancements in the DREAM (Digital Relevance Experience & Agility Management) on which business started the project initiatives based upon.
Expressional Inference Rule Engine can solve this problem. It allows business analysts to define inference rules with expressions as a normal CMS document. On publication of the inference rules document, the corresponding targeting collector for the Relevance Module will be activated right away without having to rebuild or restart the server. On depublication, the corresponding targeting collector will be deactivated right away as well.
Expressional Inference Rule Engine is a simple inference engine implementation enabling to write expressions to define Forward-chaining-based inference rules. It takes input variables. Some are built-in input variables such as request-related data (e.g., HTTP headers, URL, datetime, etc.), and some others can be added as custom POJO extensions in projects (e.g., CRM data, weather data, visitor analytics data, etc.). It executes the rule expressions defined in the document to return or deduce an inferential goal value in an inferential goal variable.
By using Expressional Inference Rule Engine, the feedback loop between business and development can cycle faster, stay healthy and keep the DREAM (Digital Relevance Experience & Agility Management) moving ahead in the right direction.
Problem
In the feedback loop with Relevance Module, the lifecycle of iterations could have 4 phases like the following diagram.
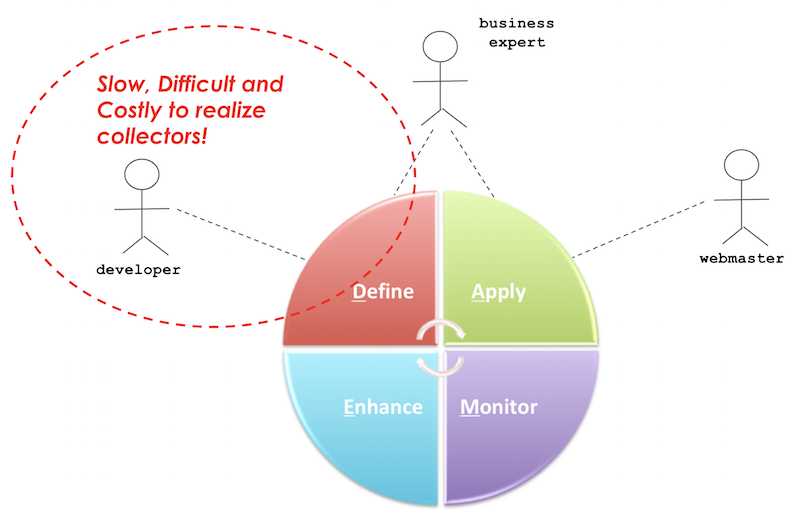
- Define: Business analyst defines the goal variables (e.g, the content type that a visitor is most interested in) to collect, and development team implements/deploys collectors for those business-meaningful goal variables.
- Apply: Business analyst defines targeting characteristics (and optionally personas) and creates targeting variants in components to personalize pages based on collected data.
- Monitor: Business analyst monitors the targeting applications and assess effectiveness of the applications.
- Enhance: Business analyst refines business-meaningful goal values (per goal variable), introduce new goal variables to collect or polish targeting data collections.
The main problem occurs in the Define phase. When a business analyst comes with a new goal variable in her or his mind, like "content category that a visitor is most interested in", development team should implement four Java classes and two ExtJS Scripts at least (see Develop a Custom Collector and Develop a Collector Plugin for detail). For example,
- MostInterestCategoryCollector.java : Targeting data collector component at runtime on delivery tier.
- MostInterestCategoryScorer.java : Targeting data scorer component at runtime on delivery tier.
- MostInterestCategoryCharacteristicPlugin.java : Targeting data characteristic selection UI on authoring tier.
- MostInterestCategoryCharacteristicPlugin.js : Targeting data characteristic selection UI script module on authoring tier.
- MostInterestCategoryCollectorPlugin.java : Targeting data collector selection UI to alter ego on authoring tier.
- MostInterestCategoryCollectorPlugin.js : Targeting data collector selection UI script module to alter ego on authoring tier.
The implementation of those components and deploying those onto the server takes notable time and effort. Business should wait for the next deployment to test, validate and apply the collectors to the system.
The Define phase must be done faster and become available even without new deployment for more business agility and quicker feedback loop.
Solution
Expressional Inference Rule Engine comes to rescue. It provides an Inference Engine that reads normal CMS documents (of document type inferenceengine:rulesdocument) containing expressions for business rules and executes the expressional rules to deduce the goal value (if any) from the input variables in the world.
Please see the diagram below.
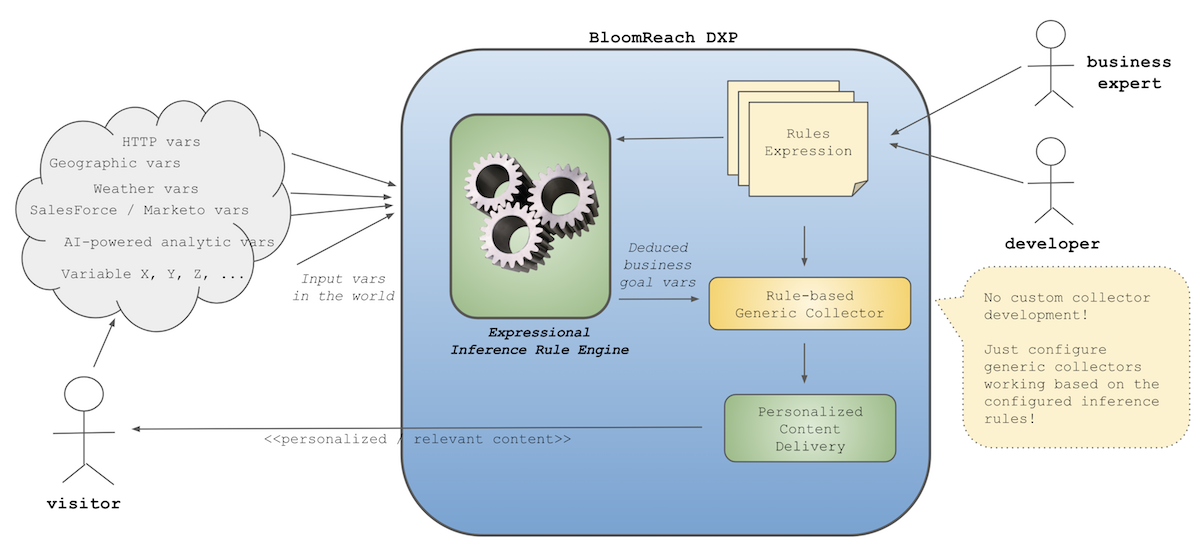
A visitor comes with input data. Some are coming directly from the visitor in the requests (e.g., cookie, IP address, etc.), some others are indirectly linked to the visitor, coming from somewhere else (e.g, weather data based on geographic location, CRM data, other accumulated history / analytic data, etc.). The input data itself, however, cannot be used as business-meaningful classified data directly in most cases. It must be filtered, classified and summarized into a more meaningful goal variable.
For example, a business analyst has a business-meaningful goal varialbe, "content category that a visitor is most interested in", in her or his mind. In this scenario, to deduce the goal variable ("interest content category"), suppose there's a new visitor visiting your website for the first time. The visitor hits a page. The page could be referred by a search engine, blog articles or a comment in a social network site. So, you want to check the "Referer" HTTP header value as an input variable to deduce the visitor's interest content category. Or you might want to check the URL (e.g, ".../news/..." -> "news" category) of the page to deduce the visitor's interest content category. You can think of anythings else to meet your business requirements. The point is, there are a lot of input variables you can take advantage of and you can use the Expressional Inference Rule Engine to deduce the goal variable from the input variables. More importantly, as you can define the inference rules in expressions inside a normal CMS document (of document type inferenceengine:rulesdocument) and you can publish the document to activate data collection right away without redeployment, you can finally make the "Define" phase a lot faster and cost-effectively for business agility.
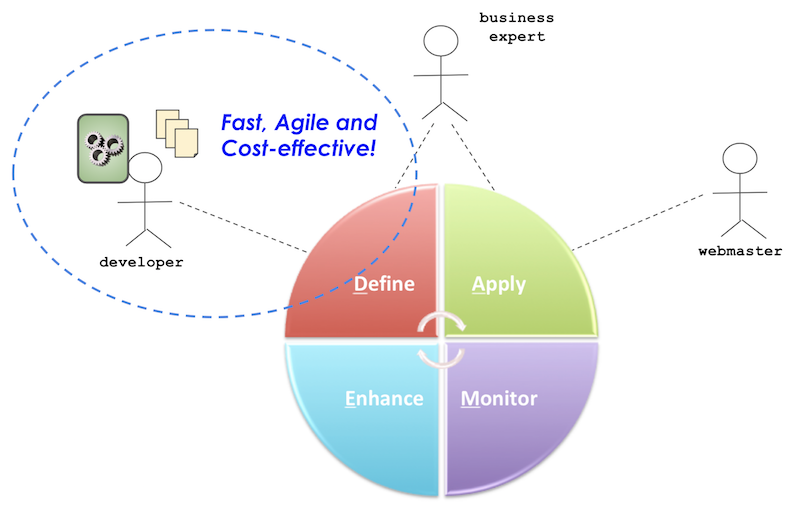
Therefore, business analysts can focus more on thinking on what kind of goal variables to collect, how effectively to target visitors with the goal variables and how to improve the data collection and effectiveness in personalization than waiting for deployment cycles delaying the Define phase.
Demo Project
Download Demo Project
Please visit the following page to download a Demo project package ZIP file (Note: you need a BloomReach Experience Developer account to download):
- https://maven.onehippo.com/maven2-enterprise/com/onehippo/cms7/hippo-addon-inference-engine-demopkg/
You can find a proper version of the demo project for you and download the ZIP artifact.
Build / Run Demo Project
After extracting the ZIP file to a folder locally, you can build and run the demo project as follows:
$ cd hippo-addon-inference-engine-demopkg-x.x.x $ mvn clean package && mvn -Pcargo.run
Demo Scenario
After startup, visit http://localhost:8080/cms/ and open "administration / Inference Rules / Determine Visitor Interest Type" document, an example inference rules definition document.
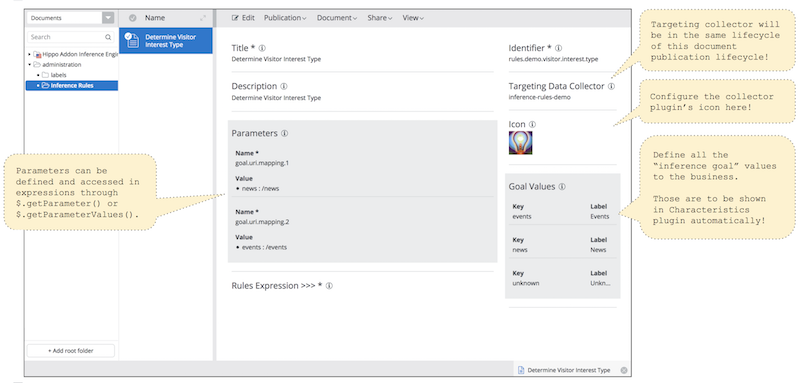
- The inference rules document has Title field which is used in targeting collector plugins as well as Description field.
- It has Identifier field by which applications can execute the specific inference rules at runtime. This must be unique.
- It has Targeting Data Collector field, which is used as Targeting Collector name in the Relevance Module. In the screenshot, the targeting collector's name is set to "inference-rules-demo" for demonstration purpose.
- It has Icon field, which is used in targeting collector plugins.
- It has Goal Values field, in which you can define all the available goal values from the goal variable in the specific business context. In the screenshot, it defines three available values: "events", "news" and "unknown". Each value has its own label to display it with labels in the Targeting Characteristic Plugin in the authoring UI.
- It has Parameters, in which you can define parameter name and values, which can be read by the expressions in the Rules Expression field.
- It has Rules Expression field which contains a JEXL based script expressions to deduce a goal value from various input variables.
By default, this Rules Expression field is hidden (collapsed). By clicking on the caption, you can expand the script view/edit pane.
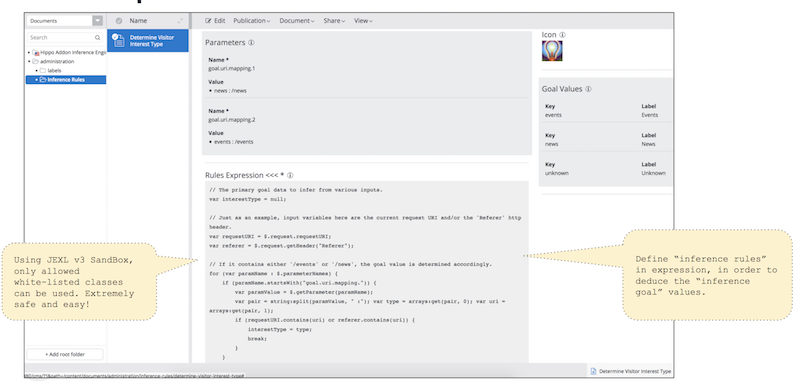
- When expanded, the Rules Expression field shows the script view/edit pane for the rules' expressions.
- If you depublish this inference rules document, the collector (named to "inference-rules-demo") will become deactivated right away.
- If you publish this inference rules document, the collector will become activated again.
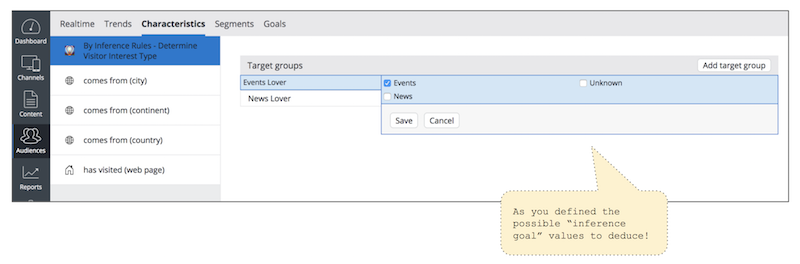
As you defined the available goal values in the inference rules document, the Targeting Characteristic Plugin will list each of those goal values as checkboxes. So, business analysts can choose one or multiple values to create a target group.
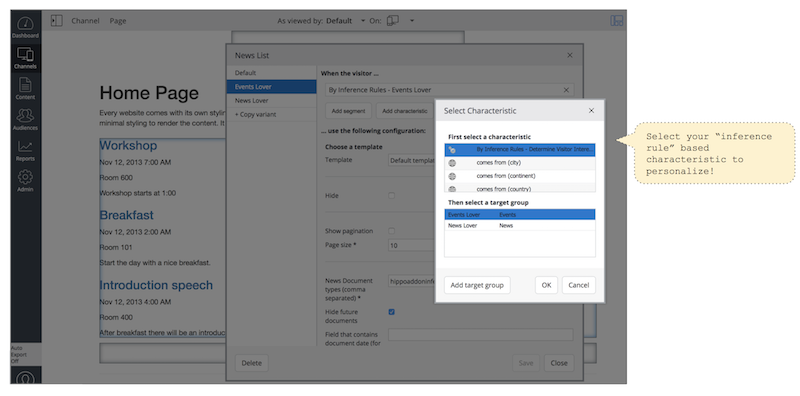
Finally, in the Channel Manager UI, business analysts can create targeting variants to specify different parameters by selecting the target groups defined by the inference rules document as shown above.