On-Premise Kubernetes Setup
Introduction
Kubernetes is an open source container orchestration engine for automating deployment, scaling, and management of containerized applications. It has become very popular among organizations that want to manage different kinds of applications within the organization in a uniform way.
Starting from version 13.1.0 of brXM, Bloomreach provides official support for running brXM in Docker containers. Since Kubernetes is simply a way of managing Docker containers, it is also possible to run brXM in a kubernetes cluster.
How to build a Docker image, how to pass the necessary environment variables to a Docker container, and ping filters as health check endpoints are mentioned in the documentation. Out of these pieces of information creating a kubernetes deployment manifest file is straightforward. There are also developer blog posts containing sample YAML files. However, running brXM in a containerized environment brings in additional challenges which are not obvious to an operations engineer configuring the kubernetes environment. In this document we list these challenges with some technical background and how to solve them.
System Architecture
-
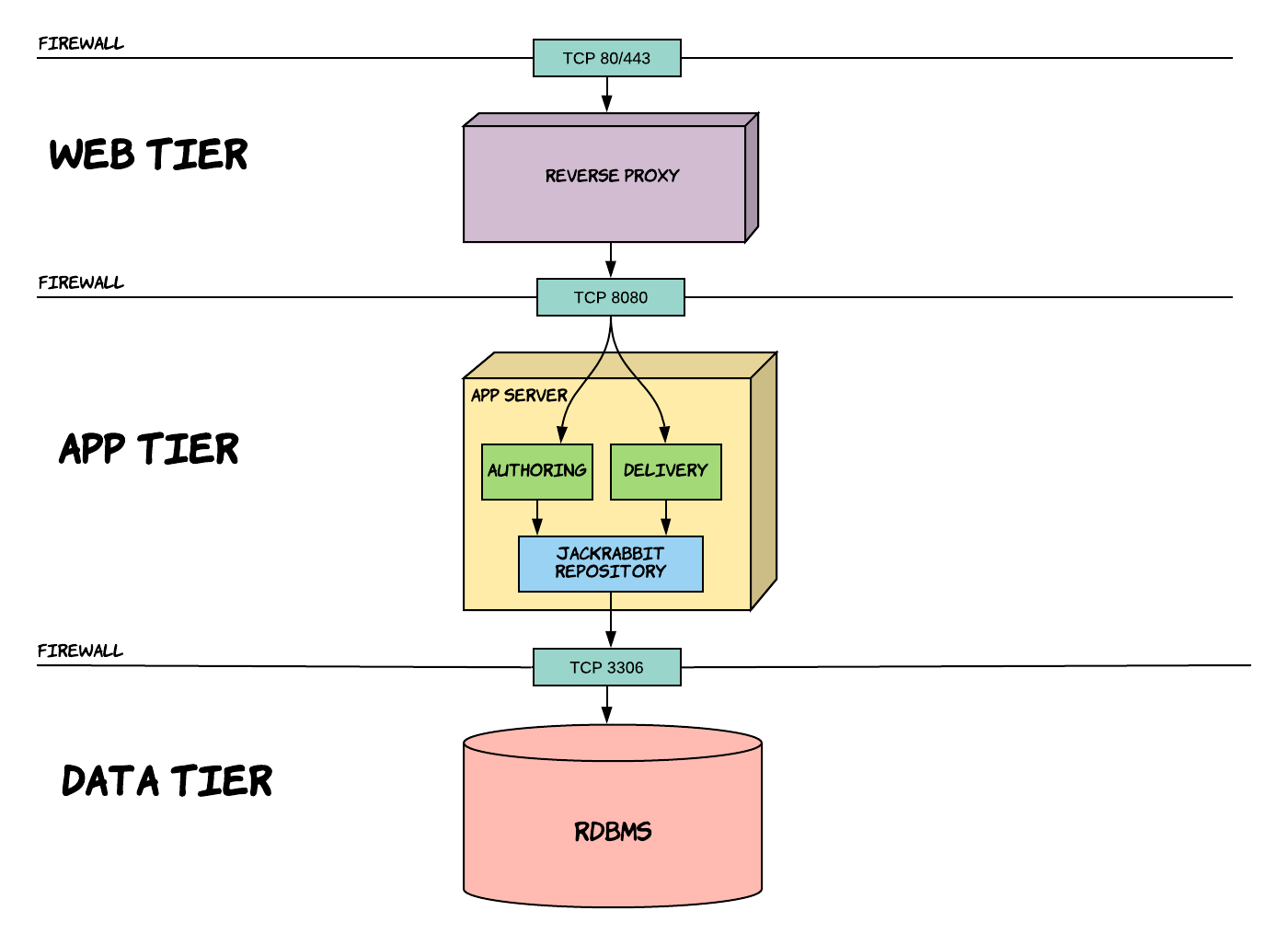
Bloomreach Experience Manager (brXM) is setup in a traditional 3-layer architecture: Web Tier, App Tier, and Data Tier
-
A standard brXM project deliverables are two war files: cms.war (aka Authoring) and site.war (aka Delivery). These wars are deployed in a supported application container such as Tomcat
-
Apache Jackrabbit is the abstraction layer between the authoring (or delivery) and the database. It is an implementation of the JCR specification. App developers never execute queries directly on the database, they go through the jackrabbit abstraction. This abstraction is what we call the “Repository”.
Clustering and The Lucene Index
-
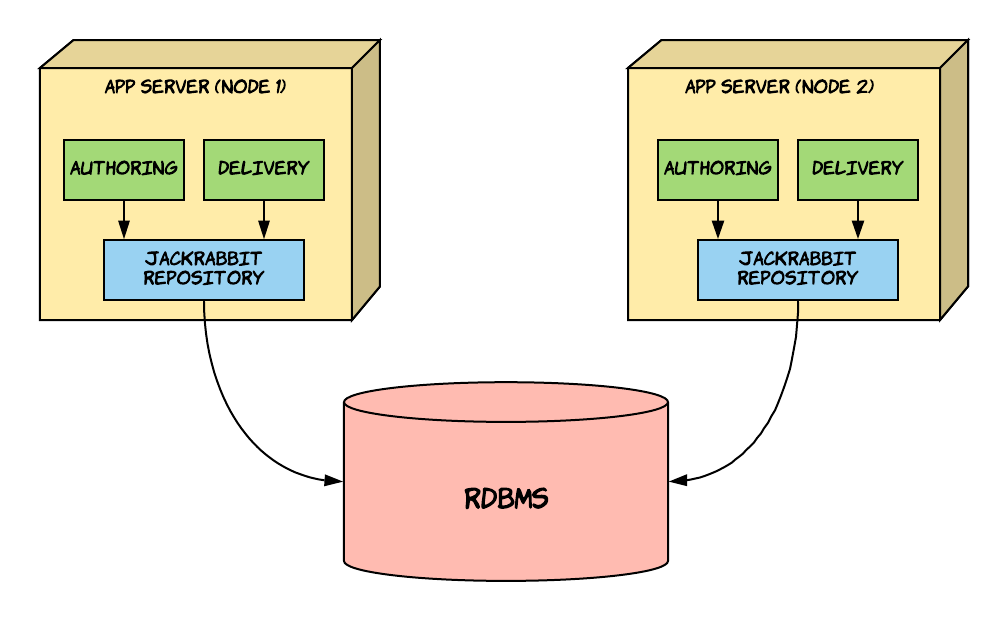
The diagram illustrates how one can horizontally scale brXM.
-
Two JCR cluster nodes are connected to the same supported relational database.
-
Each node’s repository has a unique JCR cluster node ID (Journal ID). These IDs are used internally by Jackrabbit to maintain consistency across the cluster.
-
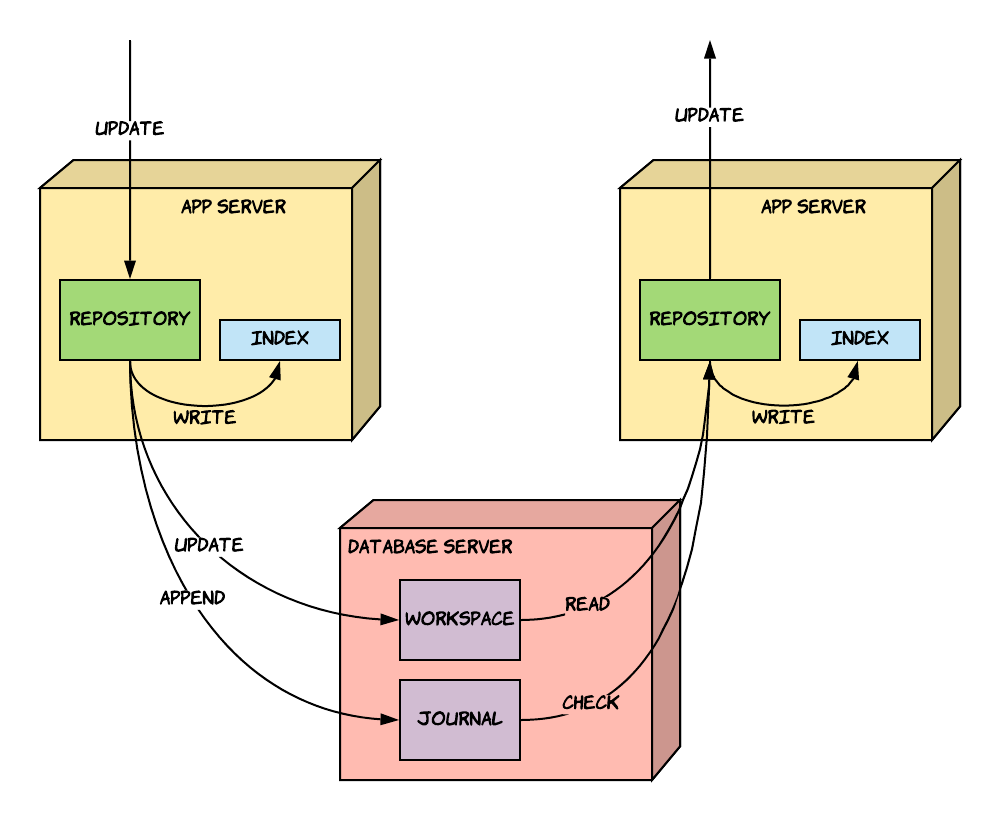
Above diagram gives a more detailed look into how Jackrabbit maintains consistency across the cluster. All JCR cluster nodes can write to the same database without conflicts.
-
What’s interesting to see is that each cluster node maintains its own Lucene index, which is kept in the local filesystem where the application container (Tomcat) is running. When nodes catch-up with other nodes on the written changes, they update their own lucene index.
-
If brXM is run in a Docker container, the lucene indexes are gone when the containers are killed. brXM app has to rebuild this index from scratch upon new deployments. This will pose a challenge in kubernetes environments since the rebuilding of the lucene index will take longer and longer over time. This problem is illustrated in the following diagrams:
-
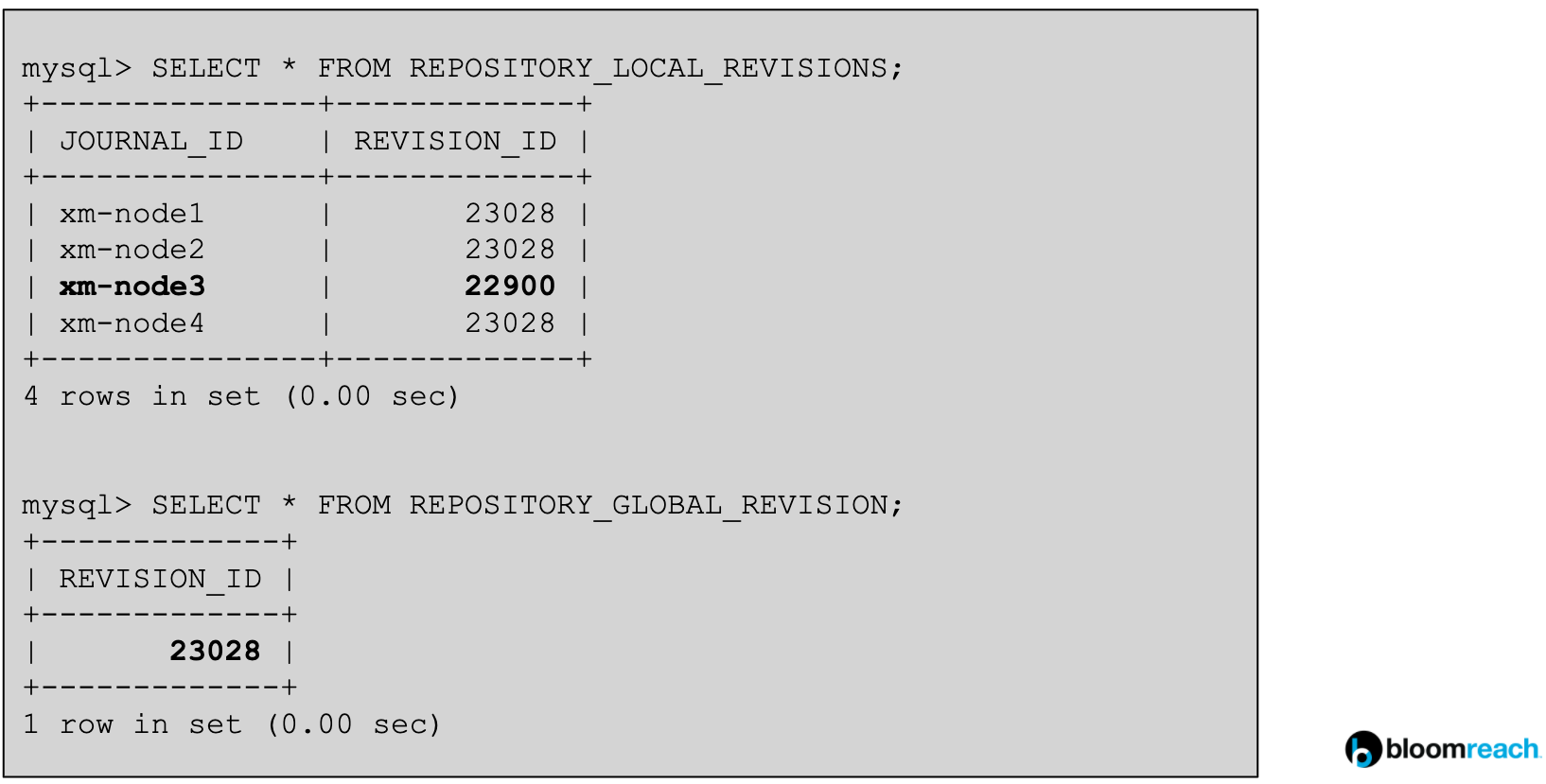
In the above diagram one can see the special tables within the underlying relational database through which consistency across the cluster is maintained by Jackrabbit.
-
REPOSITORY_LOCAL_REVISIONS table contains information about each JCR cluster node’s revision id.
-
JOURNAL_ID is the JCR cluster node ID which was mentioned before in this document.
-
REVISION_ID denotes the revision number each node is at. A revision is a single change on the database performed by one of the nodes in the cluster.
-
REPOSITORY_GLOBAL_REVISION table contains the value for the highest revision number in the cluster. This value will eventually be reached by all the active nodes at some point.
-
We can see that the highest revision number is “23028”. Cluster nodes 1, 2 and 4 seem to have caught up with this number. xm-node3 is either in the process of catching up, or it is dead. There’s no built-in mechanism to clean up dead(inactive) nodes’ rows from this table. (More on this issue later)
-
In containerized deployments, the JOURNAL_IDs ( JCR cluster node IDs) are assigned randomly (By default it’s “$(hostname -f)” , can also be assigned externally via an environment variable, but each one has to be unique!)

-
The above diagram displays a scenario where xm-node-3 is dead/killed.
-
The highest revision id in the cluster is 30000, as this is the value in the REPOSITORY_GLOBAL_REVISION table.
-
Nodes xm-node1, xm-node2, and xm-node4 seem to have caught up with this number.
-
xm-node3 is not caught up as it is stuck at 29900, because it is dead/killed.
-
Kubernetes simply recreates the pod running brXM, so a new JCR cluster node joins the cluster. It gets a random id: “random-id”
-
The new starting container has revision id 3, as it is in the process of catching up with the cluster from scratch. This is where the challenge lies: Over time, the new containers will have to catch up to higher and higher revision numbers. Deployments of brXM will get slower and slower if this problem is not tackled.
-
We can use the Lucene Index Export Plugin to speed up deployments. This plugin allows one to export a lucene index from one of the running cms instances. This export is a zip file which can be unzipped at a certain location in pods running brXM.
-
For example, if a lucene index export was taken from xm-node1 while it was at revision 25000 then the newly deployed “random-id” pod could first unzip this export at a specific location and then start from revision 25000 to build its index rather than starting from 0. This greatly reduces the deployment time.
-
The more recently taken a lucene index export is, the faster the new deployments are which make use of said index.
-
Note that if an old database backup is restored onto the database, one cannot use the lucene indexes taken after the said backup was taken. For this reason, it is also recommended to backup the lucene index exports by date.
Session Affinity
One limitation of the authoring (CMS) application is that it is a stateful application. This is not ideal for cloud-based environments because it requires additional work in load-balancers/web servers to get brXM CMS to work properly. The CMS application requires that there be a session-affinity setup. Session affinity means the user who’s connected to one cms pod should keep using the same pod in subsequent requests. Without the session affinity setup, brXM pods that have the cms.war cannot be scaled horizontally.
Bloomreach recommends setting up cookie-based session affinity. There are many ways to solve this requirement. For example in kubernetes this can be achieved with an ingress annotation such as https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/annotations/#session-affinity
Note that the session affinity requirement cannot be solved by “externalizing” the session as many clients have already inquired (using Redis for example). This is because the session used by the application contains an unserializable object and the reimplementing the system around this limitation is a significant amount of work. There is also a potential performance concern, in that the server-side session can contain a significant amount of GUI state data which would be slow to propagate between nodes on each request. Session affinity avoids the need for cluster nodes to serialize and deserialize this state on each request. Because of these reasons, the session affinity requirement unfortunately has to be solved at the infrastructure level.
Session Affinity and Downscaling
Because of the session affinity requirement, downscaling brXM pods becomes problematic for users who are logged into the CMS. Since users of CMS have to keep using the same pod, the session for the application container within the pod is lost when the pod is killed.
The downscaling of brXM pods will have to occur during upgrades to kubernetes itself. If no special action is taken there will be work disruption in the CMS. Bloomreach Cloud has a special session draining implementation to get around this issue. This implementation makes sure the traffic is moved from old to new pods while monitoring the number of logged in users within the CMS.
Deployment Model
Backwards Compatibility
A brXM project deliverable (a Docker image of the current state of the project) is said to be backwards-compatible when it satisfies the conditions mentioned in the documentation. To be on the safe side most deployable images can be considered as backwards-incompatible; especially in the early stages of brXM project development (since there will be many document type related changes as the project content model takes more concrete form). If a backwards-incompatible distribution is deployed against a database, the only supported way of deploying a previous version of the application against the same database is restoring the previous state of the database first before deployment. Therefore the backwards-compatibility of the Docker image affects the choice of deployment model.
The Bloomreach Cloud hosting offering (BRC) provides the option to choose the deployment model per deployment.
Rolling Updates
By default, in kubernetes deployments are done in the “rolling deployment” fashion. This means for a brief moment during deployment there are brXM apps with incompatible versions connected to the same database. The higher, backwards-incompatible version of the application will affect the older version application pods. Therefore, this is not a supported deployment model to deploy backwards-incompatible images.
In most circumstances a backwards-incompatible change mainly impacts the site rendering because the client has changed something that is important for their pages and components. Older pods that haven’t been upgraded spend some time feeding new data to old implementation code, which fails in unpredictable ways for whatever requests happen to be in flight during the transition.
In some cases, and in particular for brXM major version upgrades, the side-effects can be difficult-to-debug Jackrabbit-level inconsistencies with built-in node types. The rolling deployment model MUST NOT be used for major version brXM upgrades.
Although this deployment model is the easiest to set up, it does come with very strong caveats. However, many clients still choose this deployment model. If this model is chosen, it is very important to have the ability to rollback the database to a stable state and reinitiate a deployment with a suitable image.
Start-Stop (Recreate)
The start-stop deployment strategy (or “Recreate” in kubernetes terms) means stopping all running pods before deploying pods with the new version of the application. This model will prevent issues that may arise from backwards-incompatibility but it comes with the price of downtime during deployment. If some downtime is acceptable, it is advisable to go for this deployment model. This is most likely to be the case for a development environment or an internal testing environment. It can also be acceptable for some types of intranet use cases, where downtime during non-business hours can be arranged. It is much less likely to be suitable for a public-facing website.
Note that if rollback to a previous version is necessary, a compatible database backup must be restored before deployment (in case of non-backwards compatible project images). The new version of the application might have changed the database in an incompatible way.
Blue-Green
In blue-green deployments one maintains two identical environments (brXM and database). One is called blue, the other green. At any given time only one of these environments is active or receiving traffic. Development teams prepare the non-active environment for deployment and when proper testing is done, switch the traffic to the new environment. Since two separate databases are used there is no worry about backwards compatibility. The deployment process goes like the following:
-
The deployment team calls for a “content freeze”, declaring within the organization that no new content should be created, otherwise these changes will be lost. This content freeze is necessary since the deployment team is about to copy the active environment’s database to the non-active one (blue if green is active, or vice versa). There is a plugin available, Synchronization addon, which makes it possible to have document management operations synchronized across blue to green. This minimizes the time for a content freeze. There are specific limitations on the use of this plugin, so please consult the documentation and consider contacting support if you are interested in this option.
-
Bloomreach Cloud offering provides a mechanism for restricting access to the CMS or the site during content freeze.
-
-
The deployment team creates a database backup from the active environment.The deployment team restores the said database backup to the non-active environment’s database.
-
The deployment team deploys the new version of brXM project to the non-active environment.
-
Some post-deployment steps are taken, some validation / testing is performed. At this point the active environment is still the older version.
-
The stakeholders decide that the non-active environment is good to become the active environment. A switch in the traffic is performed. The switch can be performed at the ingress level in kubernetes.
The blue-green deployment model has the advantage of not causing downtime for site visitors. It also prevents strange and hard to debug issues that may arise from deploying backwards-incompatible images. Although this comes with some disadvantages too: The underlying infrastructure becomes more complex to maintain, as there are now two environments to manage. There is an organizational challenge as well, since a content freeze needs to be communicated effectively. This also makes automation of blue-green more difficult.
Repository Maintenance
Over time, the database backing the brXM Jackrabbit repository accumulates data that is obsolete for current operations. Periodically, one has to execute SQL queries against the database to clean up this redundant data and prevent performance degradation. More information on this topic can be found in the documentation.
There are 3 queries to be executed which are mentioned in the documentation. The first two are about cleaning up the old revision entries from the database. The table REPOSITORY_LOCAL_REVISIONS holds the information on up to which journal entry the node in the cluster has caught up. Entries older than the lowest revision in that table can be safely deleted from the REPOSITORY_JOURNAL tables. Executing these queries does not require any prior information about the cluster nodes and their ids: These SQL queries are static, not dynamic.
There is one more query that should be executed which is dynamic and that is about cleaning up the entries from the database that are associated with the inactive (dead) jackrabbit cluster nodes.
DELETE FROM REPOSITORY_LOCAL_REVISIONS WHERE JOURNAL_ID NOT IN (%s) AND JOURNAL_ID NOT LIKE '_HIPPO_EXTERNAL%%'
In the query above one would replace “%s” with the array of active pod ids.
To illustrate this consider the following diagram:
-
The above diagram displays a scenario where xm-node-3 is dead/killed. This was explained previously in the Clustering and The Lucene Index section.
-
Above, xm-node3 died or was killed. It will never become active anymore, as pods in the kubernetes environment will be assigned random JOURNAL_IDs as they start up.
-
The entry in the xm-node3 in the REPOSITORY_LOCAL_REVISIONS table should now be removed since xm-node3 will never be active again. Why can’t we just leave this entry here? Because leaving this entry here will cause the other repository maintenance queries to not clean up the revision table much (if not at all!) From the documentation: “Entries older than the lowest revision in that table can be safely deleted from the REPOSITORY_JOURNAL tables.” If xm-node3 is not cleaned up, the lowest revision in this table will remain quite low!
-
The main challenge in repository maintenance of brXM lies in finding the answer to the following question: How does one detect which JCR journal ids are inactive? Note that in the above diagram it could also be the case that xm-node3 is active and it is merely catching up with other JCR cluster nodes. This shows that this problem is not trivial to solve. There are two ways of finding out the inactive node ids:
-
The first and preferred approach of finding out the inactive JCR cluster node ids (journal ids) is simply asking the Kubernetes API server. The IDs in the above diagram are simply named that way for demonstration purposes. In the kubernetes environment these ids contain the pod names within the cluster. This is because by default the assignment of JCR journal id is “$(hostname -f)”. Therefore, it is possible to query the kube-apiserver within the kubernetes cluster to find out the active pod names. Once these names are found, one can find out which entries in the REPOSITORY_LOCAL_REVISIONS should be removed. There’s a locally runnable (minikube) implementation of this which includes talking to the kube-apiserver and executing the queries.
-
An alternative approach is to deduce the inactive ids with a heuristic. Consider the diagram above. The highest revision is 30000 as this is the value in the REPOSITORY_GLOBAL_REVISION table. Therefore one can think of a heuristic such as: “I will consider journal entries that are lower than, say, 15000 (half) to belong to inactive nodes”. Therefore by querying the database one can deduce which journal id entries are inactive (forever dead). Some clients have to go for this approach as they are not allowed to create serviceaccount objects within their organization to be able to talk to theKubernetes API server mentioned in the previous bullet point.
-
A Word of Caution Regarding Native Jackrabbit Janitor Process
Apache Jackrabbit provides a ‘janitor’ task which automatically removes old revisions. Although at first this sounds like an automatic solution to the issues described above, it is not. The usage of Jackrabbit Janitor is discouraged in cloud environments. Janitor makes it difficult to add new jackrabbit nodes to the cluster. Also, the janitor will not delete the ‘forever dead’ jackrabbit node entries from the REPOSITORY_LOCAL_REVISIONS table. There is no option but having an external process taking care of maintaining the revision tables in the database.
In our documentation the repository.xml examples contain ‘janitorEnabled=true’. This setting is provided as enabled by default for traditional (non-containerized), on-premise deployments.
Recommended Architecture
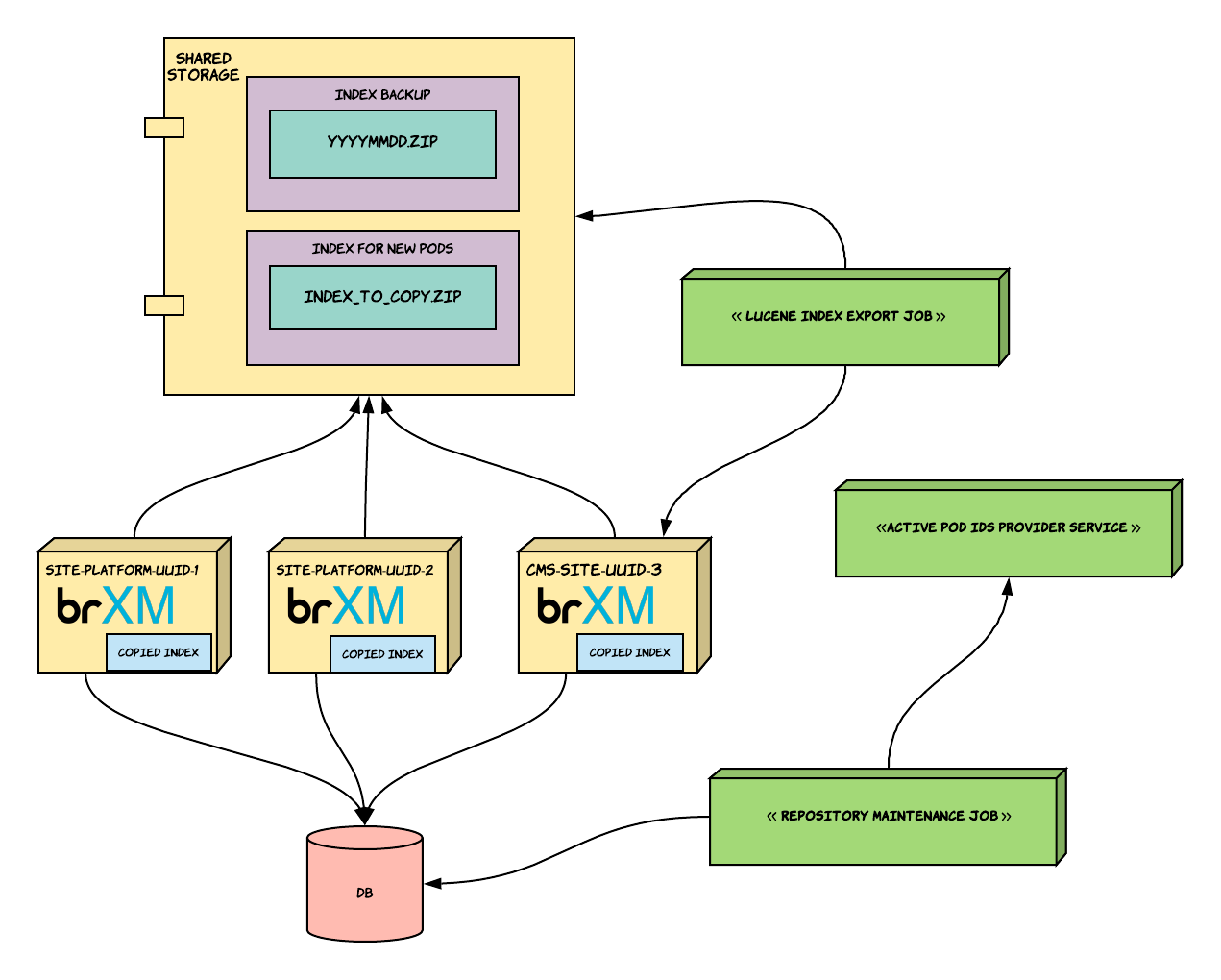
-
The above diagram illustrates how the kubernetes cluster looks like with brXM pods and accompanying maintenance services.
-
The brXM pods are connected to the same relational database.
-
The brXM pods all have access to a shared storage space. This could be NFS, EFS, Google Cloud FileStore etc. This shared storage space is mounted to the pods via the Persistent Volumes abstraction in kubernetes.
-
In the shared storage, the “Index For New Pods” directory is where the ready-to-use Lucene index export is kept. The “index_to_copy.zip” zip file is used by all brXM pods on startup. On startup, brXM pods can copy this file to their own file system inside the Docker container and unzip it in their repository. The following lines can be added to the brXM Docker startup script at src/main/docker/scripts/docker-entrypoint.sh before the start of tomcat to achieve this:
if [[ -e "${LUCENE_INDEX_FILE_PATH}" ]]; then echo "Extracting lucene index export..." mkdir -p ${REPO_PATH}/workspaces/default/index/ unzip ${LUCENE_INDEX_FILE_PATH} -d ${REPO_PATH}/workspaces/default/index/ fi -
The Lucene Index Export Job is responsible for pulling the lucene index and saving it in the “Index For New Pods” directory in the shared storage space.
-
Note that there’s a potential concurrency issue here. If a new pod is starting up and copying the index from the shared storage while the lucene index export job is running, there will be issues. That is why the example implementation project (brxm-lucene-index-exporter) first downloads the zip to a temporary location and then does an atomic swap. Bloomreach Cloud follows a similar approach, relying on the linux’s ‘mv’ command for atomicity.
-
-
The Lucene Index Export Job also makes back ups of the lucene index exports it pulls. These backups are saved in the “Index Backup” directory in the shared storage space. The zip files should follow some kind of a convention based on date (yyyymmdd.zip) so that it is easy to identify which export to use in case of a database backup restore. If for some reason a database backup was restored which was taken some time ago, one would have to use the lucene index export taken before the said database backup. The example implementation also takes care of creating backups in yyyymmdd.zip format.
-
The Repository Maintenance Job is the service that periodically executes queries against the database to prevent performance degradation. It talks to an “Active Pod IDs Provider Service”. This entity is most typically the Kubernetes API Server. The example implementation is set up in this way. However, this communication between the Repository Maintenance Job and the Kubernetes API Server requires a serviceaccount Kubernetes object to be present which grants the necessary pod-reader permissions to the Repository Maintenance Job. If it is not possible to create serviceaccount objects in your organization, you can fall back to using the heuristic method mentioned in the Repository Maintenance section.
-
The Repository Maintenance Job should be run once a day, after the daily database backup is completed. The Lucene Index Export Job should be run every 4 hours. As for the scheduling of these jobs in a periodic fashion, one can use cronjob objects within Kubernetes.
-
If it is not possible to create such cronjob objects within your organization, then there are alternative implementations such as Quartz.
-